Apache Iceberg Internals Dive Deep On Performance
In this blog I will go over how Apache Iceberg contributes to performance of compute engine. Apache Iceberg is an ACID table format designed for large-scale analytics workloads. While its consistency and schema evolution features are covered in previous blog, its impact on query performance can be equally transformative. By the end of this document, you will have a deep understanding of how Iceberg enhances performance, the trade-offs involved, and best practices for maximizing efficiency in read-heavy workloads.
Iceberg Recap
Iceberg integration with compute engine
+------------------------------------------+
| COMPUTE LAYER |
| |
| +--------+ +--------+ +--------+ |
| | Spark | | Flink | | Other | |
| +--------+ +--------+ +--------+ |
+------------------------------------------+
⬇️ ⬆️
+------------------------------------------+
| ICEBERG LAYER |
| +----------------+ +---------------+ |
| | Table Metadata | | Versioning | |
| +----------------+ +---------------+ |
| +----------------+ +---------------+ |
| | Schema Control | | Transactions | |
| +----------------+ +---------------+ |
+------------------------------------------+
⬇️ ⬆️
+------------------------------------------+
| DATA FORMAT |
| |
| +-----------+ |
| | Parquet | |
| +-----------+ |
+------------------------------------------+
⬇️ ⬆️
+------------------------------------------+
| STORAGE LAYER |
| |
| +-----+ +------+ +------+ |
| | S3 | | HDFS | | etc | |
| +-----+ +------+ +------+ |
+------------------------------------------+
Iceberg Internal High Level Design.
/\
/ \
/APIs\ ← Public APIs (Spark, Flink, Trino, REST)
/______\
/ CATALOG\ ← Catalog abstraction (Hive, Hadoop, REST, Nessie)
/__________\
/ METADATA \ ← Snapshots, Manifests, Schema, Partition spec
/______________\
/ FILE SYSTEM \ ← Object store or HDFS (S3, GCS, HDFS, etc.)
/__________________\
/ SPEC & DATA \ ← Actual data files (Parquet, Avro, ORC) + partition logic
/______________________\
/ TABLE FORMAT \ ← Iceberg core: versioned, immutable, columnar table format
/__________________________\
Here’s a high-level explanation of the Apache Iceberg stack layers and their key functions:
- APIs (Top Layer)
- Provide interface for users and applications to interact with Iceberg tables
- Enables consistent data access across different platforms
- Catalog
- Acts as the central registry for all Iceberg tables. Manages table locations and metadata.
- Supports multiple catalog implementations (AWS Glue, Hive, custom)
- Handles version control and schema evolution
- Metadata
- Tracks all changes to table data and schema
- Maintains snapshots of table state
- Manages manifest files that track data files
- Enables time travel and rollback capabilities
- File System
- Abstracts underlying storage systems
- Supports various storage options (S3, HDFS, local)
- Handles file operations and path management
- Provides consistency across different storage platforms
- Spec & Data
- Defines how data is stored and formatted
- Manages data files (typically Parquet)
- Handles file-level operations
- Implements optimizations like partition pruning
- Table Format (Foundation)
- Core specification of the table structure
- Ensures ACID transaction compliance
- Manages schema evolution rules
- Provides foundation for all other layers
Performance Mental Model
Performance of any table format is quantified by running same set of queries (usually TPC-DS) against benchmark and
experiment. Major thing to note here is driver of performance comes from compute engine. Compute engines like Apache
Spark have different planning states using which it optimizes the SQL plan. The table format facilitates the
optimization done by compute engine by providing specific information.
Mental model for performance is to find the minimum unavoidable cost and then try to find ways to remove the extra
work done by the system. Bruce Lee was on point for performance mental model by saying Hack away the unessential.
Lets apply the same mental model for iceberg performance. The bare minimum work that needs to be done is to read the
exact rows requested by the query. All the work required to reach to those query should be optimized/removed to reach
the performant workload.
Why do database developers obsess over performance
The performance gains triggers a virtuous cycle. Faster compute time will lead to
- Lower Cost - Less compute time means less resources are used which reduces your cloud bill.
- Makes Ideation Faster - Less compute time means software / data engineer will be able to run more experiments within the same time period.
- Quicker Analytics Insights – Reduces the lag in Analytics Insights reaching the front line of your business.
- Increase user adoption - Faster development cycle results in more customers/users using your product.
- More money for research and development - Increased revenue will result in more research on increasing the performance.
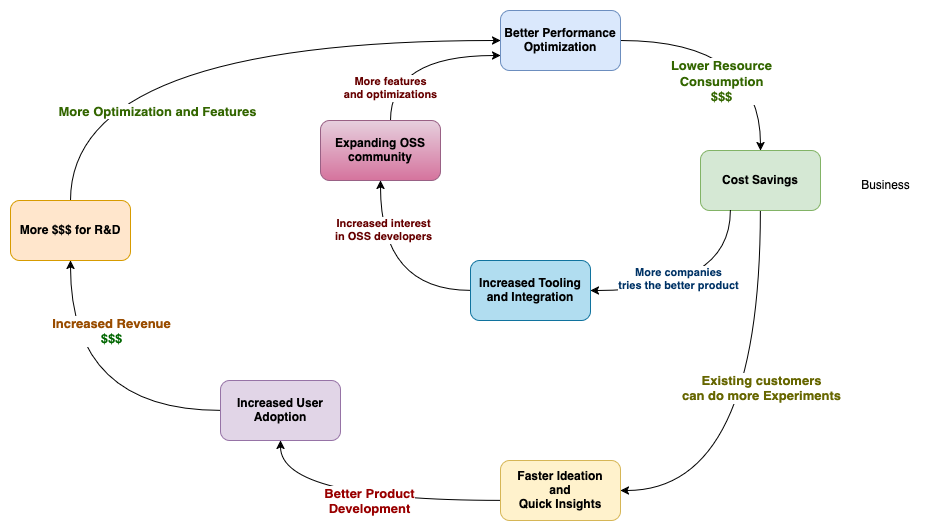
How iceberg contribute to performance optimizations
Metadata Index: Avoiding Expensive File Listing
Problem Statement:
Traditional raw parquet tables require compute engine to list directories in cloud storage, which becomes slow as the dataset grows. Listing many small files adds latency and increases compute costs.
Raw Parquet Structure
├── folder1/
│ ├── file1.parquet
│ └── file2.parquet
└── folder2/
└── file3.parquet
Problems:
- Full directory scan required
- No table-level statistics
- Upfront defining data partitions
- Changing partitioning require rewriting all data or manually tracking the changed partitioning.
How Iceberg Helps:
Iceberg provides manifest lists and manifests. This helps because:
- Instead of listing directories, Iceberg maintains structured metadata. A manifest list points to multiple manifest files, each of which contains metadata about a subset of data files. This enables Spark to quickly determine relevant files without scanning the entire directory structure.
- Automated statistics maintenance
- O(1) metadata access
Iceberg Metadata Structure
├── Manifest Lists (Quick Summary)
│ ├── Total files: 3
│ ├── Column ranges
│ └── Partition summary
├── Manifest Files
│ ├── File statistics
│ └── Column metrics
└── Data Files
└── Parquet files
Why It Matters
As per our performance mental model, we want to reduce any cost that does not directly contribute to reading only the required data. With metadata layer providing the map to required data is reducing the unnecessary compute.
// Raw Parquet: Directory Listing
// Can take minutes for large tables
long startTime = System.currentTimeMillis();
FileSystem fs = FileSystem.get(conf);
RemoteIterator<LocatedFileStatus> files = fs.listFiles(
new Path("/data/"), true);
// Iceberg: Direct Metadata Access
// Completes in milliseconds
TableScan scan = table.newScan();
Snapshot snapshot = table.currentSnapshot();
Iterable<DataFile> files = snapshot.dataFiles();
File Pruning: Scanning Only Necessary Data
File Pruning is an optimization technique that allows a system to skip reading unnecessary files or partitions during query execution.
Problem Statement:
In raw parquet tables, query engine often reads unnecessary files due to inefficient partition pruning, increasing I/O and compute costs.
-- Raw Parquet Query
SELECT * FROM parquet_table
WHERE date_col = '2024-04-09'
AND category = 'electronics';
Execution:
- Scan all directories
- Read file footers
- Apply filters
Without the table format, I have seen production environment where devs have maintained partition information in key value store to perform partition pruning. Thereby creating diy table format, in long term it’s painful to manage such systems due to required consistent maintenance, and limited feature sets.
How Iceberg Helps:
- Partition Pruning Without Directory Reads: Iceberg stores partition values inside metadata, allowing Spark to prune partitions without listing directories or reading file footers.
- Min/Max Statistics for Fast File Skipping: Each manifest stores min/max statistics for every column in a file. This enables Iceberg to eliminate files that do not contain relevant data.
-- Iceberg Query (Same SQL)
SELECT * FROM parquet_table
WHERE date_col = '2024-04-09'
AND category = 'electronics';
Execution Steps:
- Check manifest list (instant)
- Filter manifests using statistics
- Read only relevant files (effective file pruning)
Design
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Query Engine │────▶│ Iceberg Scan │────▶│ Manifest Lists │
│ (Spark/Flink) │ │ Planning │ │ Filtering │
└──────────────────┘ └──────────────────┘ └────────┬─────────┘
│
▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Data Read │◀────│ Data Files │◀────│ Manifest Files │
│ Execution │ │ Filtering │ │ Filtering │
└──────────────────┘ └──────────────────┘ └──────────────────┘
Why It Matters
With Iceberg, even non-partition columns (e.g., WHERE value = 100) can trigger file skipping via min/max stats in manifests. Parquet files must be opened to get row group stats—meaning Iceberg avoids file opens altogether in many cases. This fits back with our mental model to not let compute engine work on files that are not really needed to execute the query.
Raw Parquet: O(n) where n = total files
Iceberg: O(log n) where n = relevant files
Predicate Pushdown: Filtering at the Metadata & File Level
Predicate Pushdown is an important optimization technique in modern query engines that improves query performance by pushing filtering operations (predicates) as close as possible to the data source. This means filtering happens before data is loaded into engine’s memory, significantly reducing the amount of data that needs to be processed.
The Problem
Without effective pushdown capabilities, query engine may load unnecessary data into memory before applying filters, or have to open files to read file group stats.
// Raw Parquet Statistics
class ParquetStatistics {
// Limited to file level
MinMax<T> minMax;
long nullCount;
}
How Iceberg Helps
- Manifest Filtering: Iceberg applies predicate filtering at the manifest level, ensuring that entire file groups are skipped before query execution.
- Column-Level Filtering: Since Iceberg maintains column-level statistics, filters are applied at a fine-grained level.
// Iceberg Statistics
class IcebergStatistics {
// Multiple levels
TableStats tableStats;
ManifestStats manifestStats;
FileStats fileStats;
// Rich metrics
ValueCounts valueCounts;
NullCounts nullCounts;
NanCounts nanCounts;
}
Design
┌──────────────────────────────────────────────────────────┐
│ Query with Predicates │
└───────────────────────────┬──────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────┐
│ Predicate Analysis & Conversion │
├──────────────────────────────────────────────────────────┤
│ 1. Convert to Iceberg Expression │
│ 2. Identify Partition Predicates │
│ 3. Extract Column Predicates │
└───────────────────────────┬──────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────┐
│ Multi-level Filtering │
├─────────────────────┬─────────────────┬──────────────────┤
│ Partition Filter │ Manifest Filter │ File Filter │
└─────────────────────┴─────────────────┴──────────────────┘
Performance Gains
- Queries avoid scanning non-relevant data files.
- Reduced network and disk I/O.
- Faster query execution, particularly for selective queries.
Vectorized Reads: Efficient Columnar Processing
Vectorized Reads is a performance optimization technique that improves data reading efficiency by processing multiple rows of data simultaneously instead of one row at a time. Here’s how it works :
- Reads data in batches/vectors instead of row by row
- Processes multiple records simultaneously using CPU’s vectorized instructions
- Operates on columns rather than rows
- Utilizes modern CPU capabilities for parallel processing
The Problem:
Traditional row-wise data processing in Spark is slow, as each record is processed sequentially.
// Traditional Parquet Vectorization
class ParquetVectorizedReader {
private ColumnVector[] columnVectors;
private int batchSize = 1024;
public void readBatch() {
// Reads directly from parquet format
// Limited by parquet internal structure
for (int i = 0; i < batchSize; i++) {
readNextRow(columnVectors);
}
}
}
// Parquet Memory Management
class ParquetMemoryManager {
public ColumnVector allocateVector() {
// Fixed allocation strategy
return new ColumnVector(DEFAULT_VECTOR_SIZE);
}
}
Traditional Parquet:
- Fixed batch size: 1024
- Memory spikes
- Suboptimal CPU cache usage
How Iceberg Helps:
- Iceberg enables columnar vectorized reading, allowing query engine to process batches of data at once.
- Iceberg supports Dynamic batch sizing.
- Iceberg enables controlled memory usage.
- It can be optimized for CPU cache.
// Iceberg's Vectorized Implementation
class IcebergVectorizedReader {
private final VectorizedReader[] readers;
private final BatchReader batchReader;
public VectorHolder readBatch() {
// Optimized batch reading with metadata awareness
DataPageV2 page = pages.nextPage();
// Pre-filtered using statistics
skipUnneededPages();
return batchReader.readBatch(
readers,
page,
metadata.statistics()
);
}
}
// Iceberg Memory Management
class IcebergMemoryManager {
public ColumnVector allocateVector(
ManifestFile manifest,
ColumnStats stats
) {
// Smart allocation based on statistics
int optimalSize = calculateOptimalSize(
stats.valueCount(),
stats.nullCount(),
manifest.format()
);
return new ColumnVector(optimalSize);
}
}
// Iceberg SIMD Implementation
class VectorizedProcessor {
@Override
protected void processVector(
ColumnVector input,
ColumnVector output
) {
// Utilize CPU SIMD instructions
if (input.hasSIMDSupport()) {
processSIMD(input, output);
} else {
processScalar(input, output);
}
}
}
Design
┌────────────────────────────┐
│ Iceberg Metadata │
├────────────────────────────┤
│ - Column Statistics │
│ - Value Bounds │
│ - Null Counts │
└──────────────┬─────────────┘
│
▼
┌────────────────────────────┐
│ Vectorized Read Planning │
├────────────────────────────┤
│ 1. Pre-filter pages │
│ 2. Optimize batch size │
│ 3. Memory allocation │
└──────────────┬─────────────┘
│
▼
┌────────────────────────────┐
│ Vectorized Execution │
└────────────────────────────┘
Compaction: Improved Data locality
Compaction is a process of combining multiple small files into larger ones to optimize storage and query performance.
The Problem:
Query engine over parquet generates tons of small files, especially with frequent inserts/updates. Traditional parquet tables, lacks centralized metadata, so:
- Compaction requires a full table scan
- No insight into which files are causing performance issues.
Without proper data layout leads to inefficient scans, especially for multi-column queries.
Problems:
- High compute and I/O cost during compaction.
- No integration with table metadata — just a rewrite.
- Query performance continues degrading until compaction is done.
- Difficult to automate safely without introducing write conflicts.
How Iceberg Helps:
There are two types of compaction iceberg supports: data compaction and manifest compaction.
The goals of data file compaction are:
- Improving data locality:
- Apply data clustering to make reads more efficient.
- Increasing the amount of data read per file:
- Reduce the number of data files that must be loaded during reads.
- Reduce the number of delete files that must be applied during reads.
Data Locality
Query engine uses metadata layer to get the file stats to perform query planning. These stats are only useful if it helps with file pruning discussed above. Sorting is one of the techniques to add value to file stats. Query engine can use the file stats in metadata files to only load required files. Thus data locality can greatly influence the performance of iceberg datasets.
For example -
UNSORTED DATA FILES
+-----------------+ +-----------------+
| File 1 | | File Stats |
| 2,45,78,1,99 | | Min: 1 |
| 23,67,3,89,12 | | Max: 100 |
+-----------------+ +-----------------+
| File 2 | | File Stats |
| 5,91,34,77,2 | | Min: 1 |
| 88,13,56,9,44 | | Max: 100 |
+-----------------+ +-----------------+
| File 3 | | File Stats |
| 15,90,4,66,100 | | Min: 1 |
| 25,81,11,92,33 | | Max: 100 |
+-----------------+ +-----------------+
QUERY: WHERE value < 10
- Must scan ALL files because each file might contain values < 10
- High I/O, poor performance
VS
SORTED & COMPACTED DATA FILES
+-----------------+ +-----------------+
| File 1 | | File Stats |
| 1,2,3,4,5 | | Min: 1 |
| 6,7,8,9,10 | | Max: 10 |
+-----------------+ +-----------------+
| File 2 | | File Stats |
| 11,12,13,14,15 | | Min: 11 |
| 16,17,18,19,20 | | Max: 20 |
+-----------------+ +-----------------+
| File 3 | | File Stats |
| 21,22,23,24,25 | | Min: 21 |
| 26,27,28,29,30 | | Max: 30 |
+-----------------+ +-----------------+
QUERY: WHERE value < 10
- Only needs to scan File 1
- Skips File 2,3 based on stats
- Efficient I/O, better performance
Iceberg Compaction strategies
- BinPack Strategy
- Groups small files together and rewrites them into evenly sized, larger files, trying to minimize the total number of output files.
- Optimized for compaction run time.
- Data locality is not improved but the number of files I/O is improved.
- SortCompaction Strategy
- Rewrites files by sorting their contents on a specified key (e.g., order_date, user_id) before writing.
- Higher compaction run time.
- Data locality is improved.
- Z-order compaction Strategy
- Rewrites data files by clustering rows using Z-order curves on specified columns to optimize multi-dimensional range query performance.
- Higher compaction run time.
- Data locality is improved, better than sort compaction.
Will go more deeper into compaction on next blog.
Performance Gains:
- Better data locality.
- Faster range-based queries.
- Improved performance for queries scanning multiple columns.
Reference
- Iceberg Code Base for understanding iceberg protocol
- Iceberg Official docs for understanding iceberg specification
- Apache Iceberg The Definitive Guide for highly understanding for Iceberg.