Apache Iceberg Architecture Dive Deep
This is first part of iceberg series where I dive deep into Apache Iceberg internals. In this blog I will explain the architecture, specifications and protocols of Apache Iceberg in great details. I will go over the internal working, high level design, metadata evolution with examples for different write modes Apache Iceberg support Merge On Read, and Copy On Write. I will also go over the control flow / low level design of Apache Iceberg write path in both simplified and detailed version. I will also touch upon compaction and consistency handling of Apache Iceberg.
Prerequisite
This blog is useful to you if you have basic understanding of table formats, data warehouses and data lakes.
What is Apache Iceberg?
Apache Iceberg is an open table format that provides a set of APIs for managing large analytic datasets. It was created in 2017 by Netflix’s Ryan Blue and Daniel to overcome the challenges to maintain Hive Table format ( developed by facebook in 2009). Iceberg was originally built with several goals -
- Consistency
- Performance
- Easy to use
- Evolvability
- Scalability
Apache Iceberg High Level Design - Table Specification
Apache Iceberg is a table format specification that provides a high-level abstraction for managing large analytical tables. Here’s a breakdown of its core components:
- Catalog:
- Acts as an entry point to locate tables.
- Points to the latest metadata file in the metadata store.
- Helps track the current state of tables.
- Metadata Store:
- Maintains a history of table snapshots.
- Tracks metadata files that reference the actual data.
- Provides centralized management of table state.
- Keeps track of schema evolution, partitioning changes, and other table properties.
- Data Store:
- Contains the actual data files.
- Stores table contents in file formats like Parquet, ORC, or Avro.
- Can be located in cloud storage (S3, Azure Blob) or local filesystems.
The key benefit of Iceberg is that it abstracts away the complexity of managing these components. While users interact with what appears to be a single table, the Iceberg library handles:
- File management.
- Metadata tracking.
- Table name management.
- Version control of data.
- Schema evolution.
The Iceberg specification standardizes how these elements are represented and stored, while the library provides APIs to interact with and manipulate these components in a consistent way.
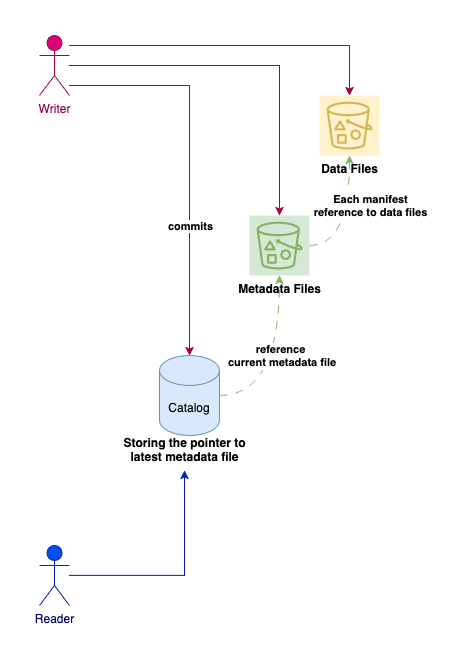
As represented in above simplified view of iceberg, data is visible to user through catalog.
- Write Path:
- Writer first writes new data files to storage
- Creates new metadata files with updated file manifests
- Validates for conflicts with existing metadata
- Commits the new snapshot to the catalog atomically
- Read Path:
- Readers only see data through the catalog
- Catalog points to the latest committed metadata file
- Metadata file contains references to valid data files
- This ensures readers only see consistent, committed data
Important Point : This means readers are isolated from concurrent writes to the data layer.
This design choice of Iceberg has been very useful in achieving complex goals
- Serializable Isolation - Since writers never modify existing data files (immutable files). New data is invisible until the commit is complete. This results in readers continue using their current snapshot during writes. No partial or uncommitted data is ever visible to readers
- Concurrency Control - Concurrent writes results in conflicts. With isolation of writes makes it easy to detect conflicts using the metadata layer over using the data layer. The Conflict detection happens at commit time, and only one writer can successfully commit at a time. Failed commits will be retried, and don’t affect readers or data consistency.
Going Deeper Into Iceberg Table Specification
Iceberg creates a tree like structure to manage the metadata. It has catalog which tracks the location of current metafile. Metadata file tracks the log of snapshots. Each snapshot tracks one manifest list. Each manifest list tracks list of manifest files for the snapshot. Each manifest file tracks list of data files.
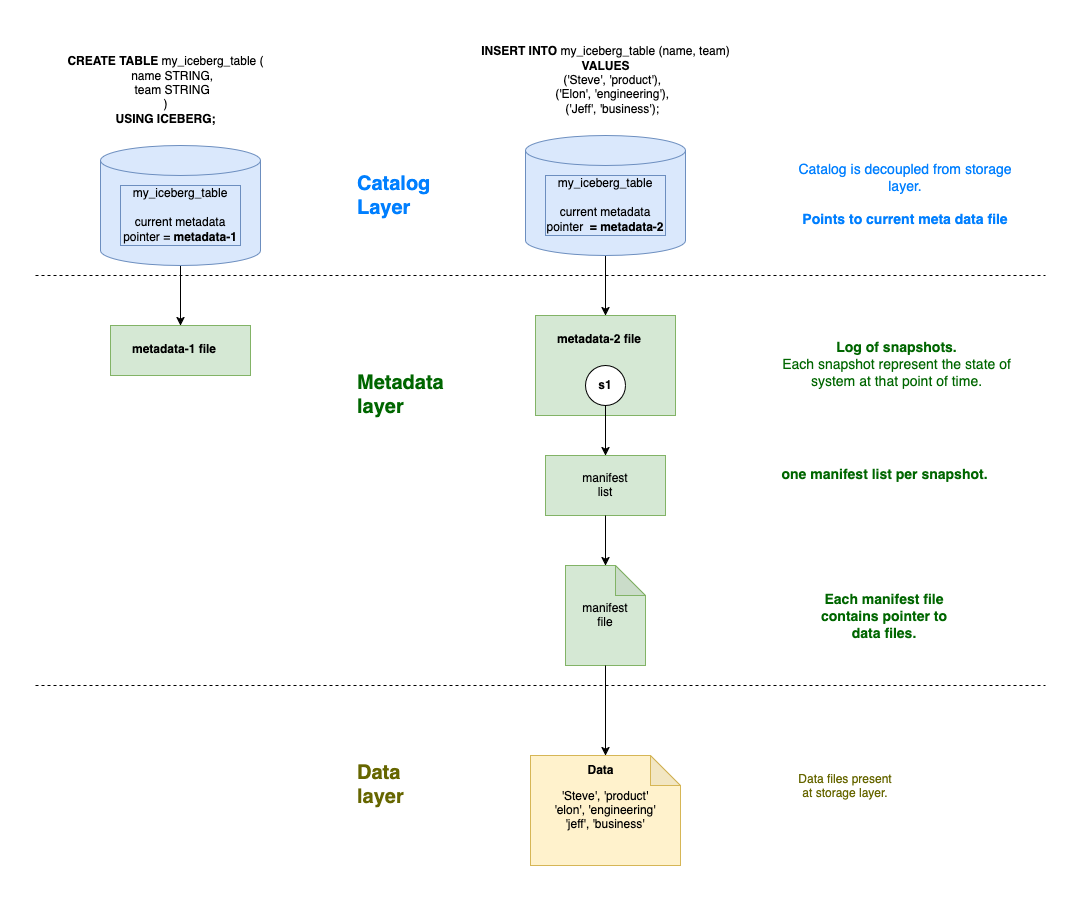
Let me break down Iceberg’s tree-like metadata structure in more detail:
- Catalog (Root)
- Top-level pointer.
- Tracks the current metadata file location.
- Enables atomic updates through single-point updates ( compare and swap technique ).
- Can be implemented using various catalog implementations (Hive, Glue, etc.).
- Metadata Files
- Contains snapshot information.
- Maintains a log of all snapshots.
- Tracks schema evolution.
- Stores table properties and configurations.
- Points to manifest lists.
- Manifest Lists
- Each snapshot has one manifest list.
- Acts as an index of manifest files.
- Helps in organizing manifests by partition.
- Enables efficient filtering at the manifest level.
- Manifest Files
- Contains list of data files.
- Stores partition data.
- Maintains file-level statistics.
- Records file additions and deletions.
- Enables predicate push down ( query optimization ).
- Data Files
- Actual data stored in file formats like Parquet.
- Immutable once written.
- Contains the table’s data records.
This structure allows Iceberg to provide features like:
- Snapshot isolation
- Schema evolution
- Partition evolution
- Time travel queries
- Incremental processing
Seeing Under The Hood of Iceberg MetaData Files.
Bellow does not contain the detailed schema, please check iceberg official documentation for this. Going over these schema will give a simple east to understand view of what it contains.
<table-metadata-location>/metadata/v<version-number>.metadata.json
┌───────────────────────────────────────────────────┐
│ Metadata │
│ (table metadata file tracking log of snapshots.) │
│------------------------------------------------- │
│ - Table schema │
│ - Snapshot list │
│ - Current snapshot ID │
│ - Partition spec & sort order │
│ - Table properties │
└───────────────────────────────────────────────────┘
│ │ │
▼ ▼ ▼
Snapshot list is present in above metadata file,
and shown here as separate block just for explaining.
┌──────────────────────────────────┐
│ Snapshot │
│ (snapshot in metadata │
│ tracks manifest list) │
│----------------------------------│
│ - Snapshot ID │
│ - Manifest list location │
│ - Timestamp │
│ - Summary (commit metadata) │
└──────────────────────────────────┘
│
▼
<table-metadata-location>/metadata/snap-<snapshot-id>-<random-uuid>.avro
┌──────────────────────────────────────────┐
│ Manifest List │
│ (list of manifest files per snapshot) │
│------------------------------------- │
│ - Location of the manifest file │
│ - added_snapshot_id │
└──────────────────────────────────────────┘
│ │ │
▼ ▼ ▼
<table-metadata-location>/metadata/<manifest-file-id>-<random-uuid>.avro
┌──────────────────────────────────┐
│ Manifest Files │
│----------------------------------│
│ - References to data files │
│ - Partition-level stats │
│ - File existence (added/deleted) │
│ - Data file format (Parquet, ORC)│
└──────────────────────────────────┘
│ │ │
▼ ▼ ▼
<table-location>/data/<partition-path>/<unique-file-name>.<format>
┌──────────────────────────────────┐
│ Data Files │
│----------------------------------│
│ - Actual data storage (e.g., │
│ Parquet, ORC, Avro files) │
│ - Column statistics │
└──────────────────────────────────┘
Understanding Iceberg Metadata Store Evolution With New Writes
For every write operation in an Apache Iceberg table, a new snapshot is created. This process starts with generating new data files and updating or adding manifest files that track these changes. A new manifest list is then created, referencing both newly added manifest files and existing ones that remain unchanged. This ensures efficient tracking of table modifications without rewriting unchanged metadata. Once the manifest list is prepared, Iceberg records it as part of the new snapshot, assigning it a unique snapshot ID. Finally, a new table metadata file (metadata.json) is written, pointing to the latest snapshot, making it the current state of the table while preserving all previous snapshots for time travel and rollback capabilities.
Understanding Apache Iceberg Table Formats: Merge-on-Read (MoR) vs Copy-on-Write (CoW)
Iceberg supports two write approaches -
- Copy on write
- Merge On read
Copy On Write
In Copy-on-Write (CoW), when a row is updated or deleted, instead of modifying the original data file, a new data file is created containing the modified records while preserving the original file. This approach ensures data consistency and enables time travel capabilities by maintaining previous versions of the data.
Pros
- Optimized for read heavy workloads. The data is in final state and there is no work of merging data at query time.
Cons
- Not efficient for frequent updates/deletes.
- Higher storage cost due to complete file rewrites.
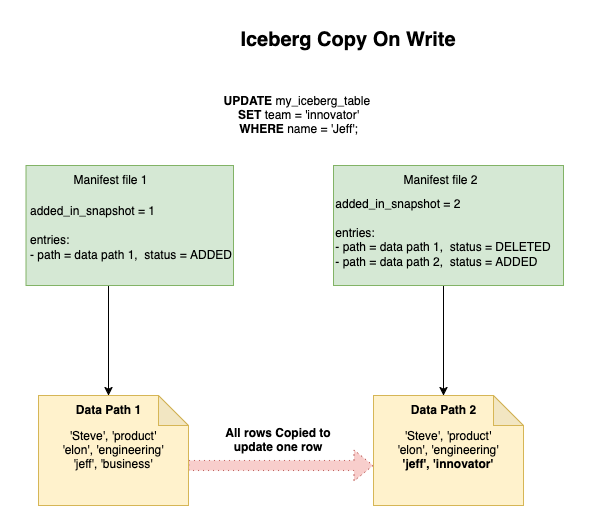
Detailed Example for Metadata store evolution During COW
To understand how write impacts the metadata store we will run the following queries on an empty table and see how the metadata store evolves-
INSERT INTO my_iceberg_table (name, team)
VALUES
('Steve', 'product'),
('Elon', 'engineering'),
('Jeff', 'business');
INSERT INTO my_iceberg_table (name, team)
VALUES
('Warren', 'account');
UPDATE my_iceberg_table
SET team = 'innovator' WHERE name = 'Jeff';
UPDATE my_iceberg_table
SET team = 'space' WHERE name = 'Elon';
DELETE FROM my_iceberg_table
WHERE name = 'Steve';
Merge On Read
In Merge-on-Read (MoR), when data is modified (updated or deleted), the changes are initially recorded in delta files rather than creating new base data files immediately. These delta files store the modifications separately until a compaction operation merges them with the base files. This approach optimizes write performance by deferring the expensive merge operations while maintaining data consistency.
Iceberg supports two types of delete operations in MoR tables - Positional deletes and Equality deletes.
Positional deletes in MoR work by maintaining position-based references to the records that need to be deleted. These delete files store the file and position information of the records to be removed, rather than the actual record data. During read operations, these positional delete files are used to filter out the deleted records from the base data files.
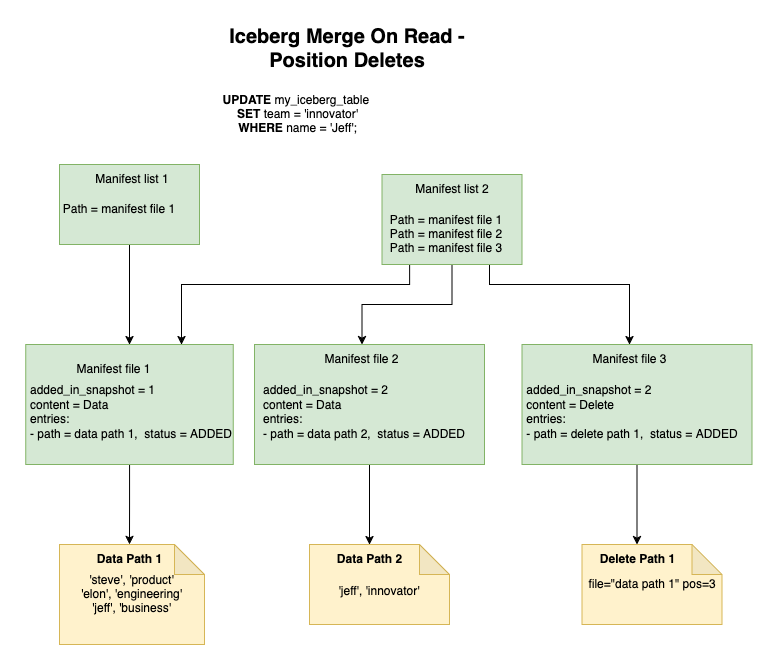
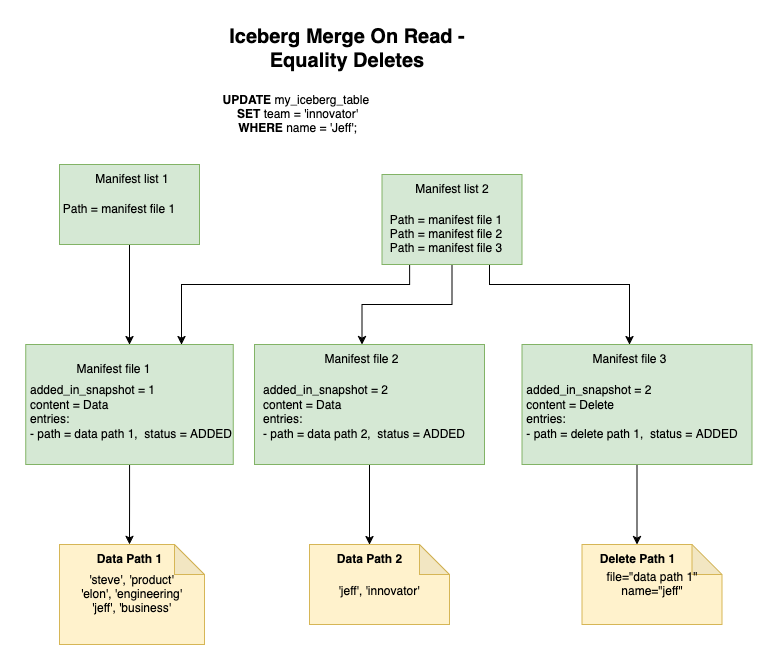
Equality deletes in MoR operate by storing the equality conditions that identify which records should be deleted. Instead of tracking positions, these delete files contain the values of specific columns that match the records to be removed. When reading data, the system applies these equality conditions to filter out deleted records, making it particularly useful for scenarios where multiple records might match the delete criteria.
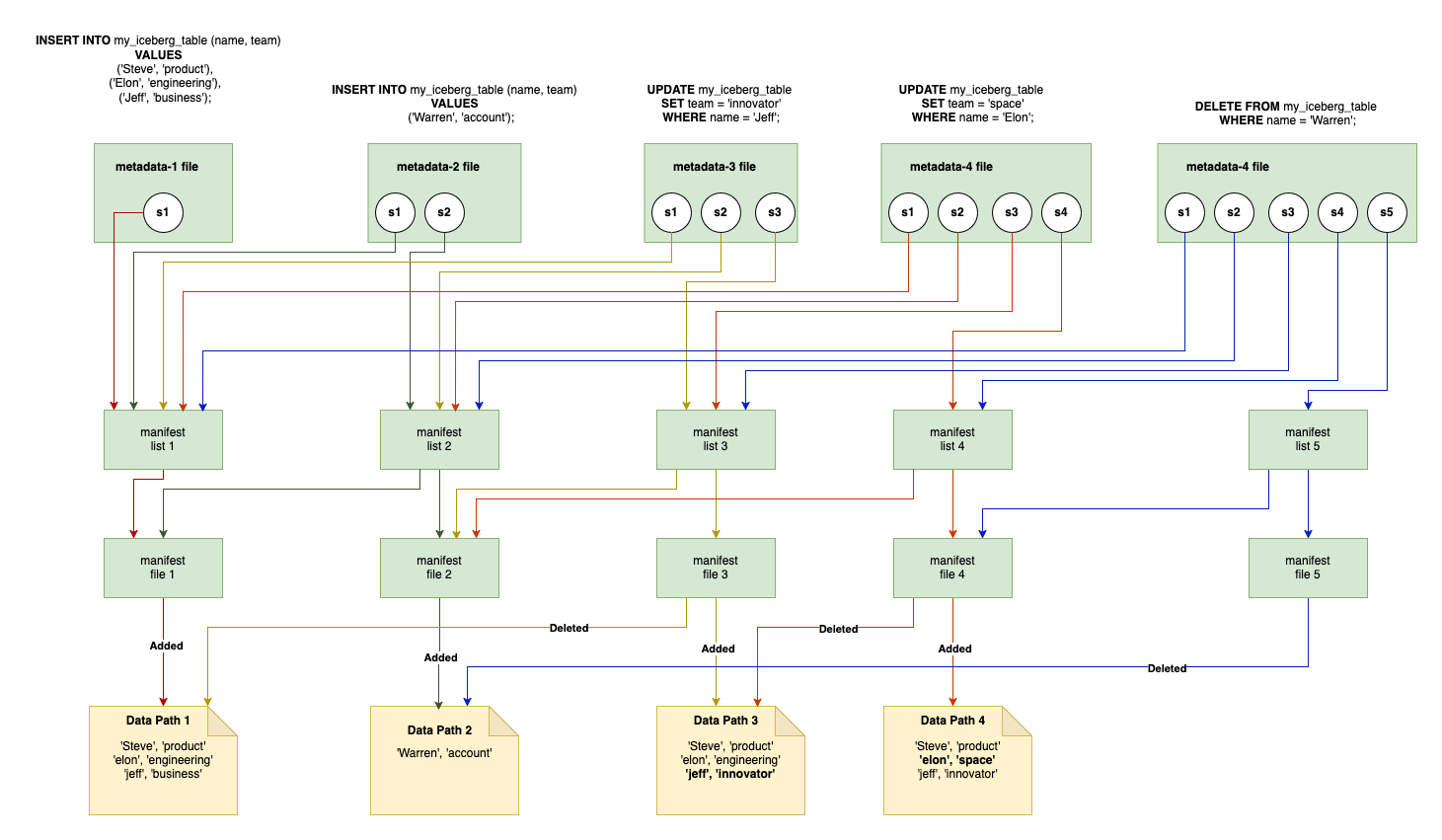
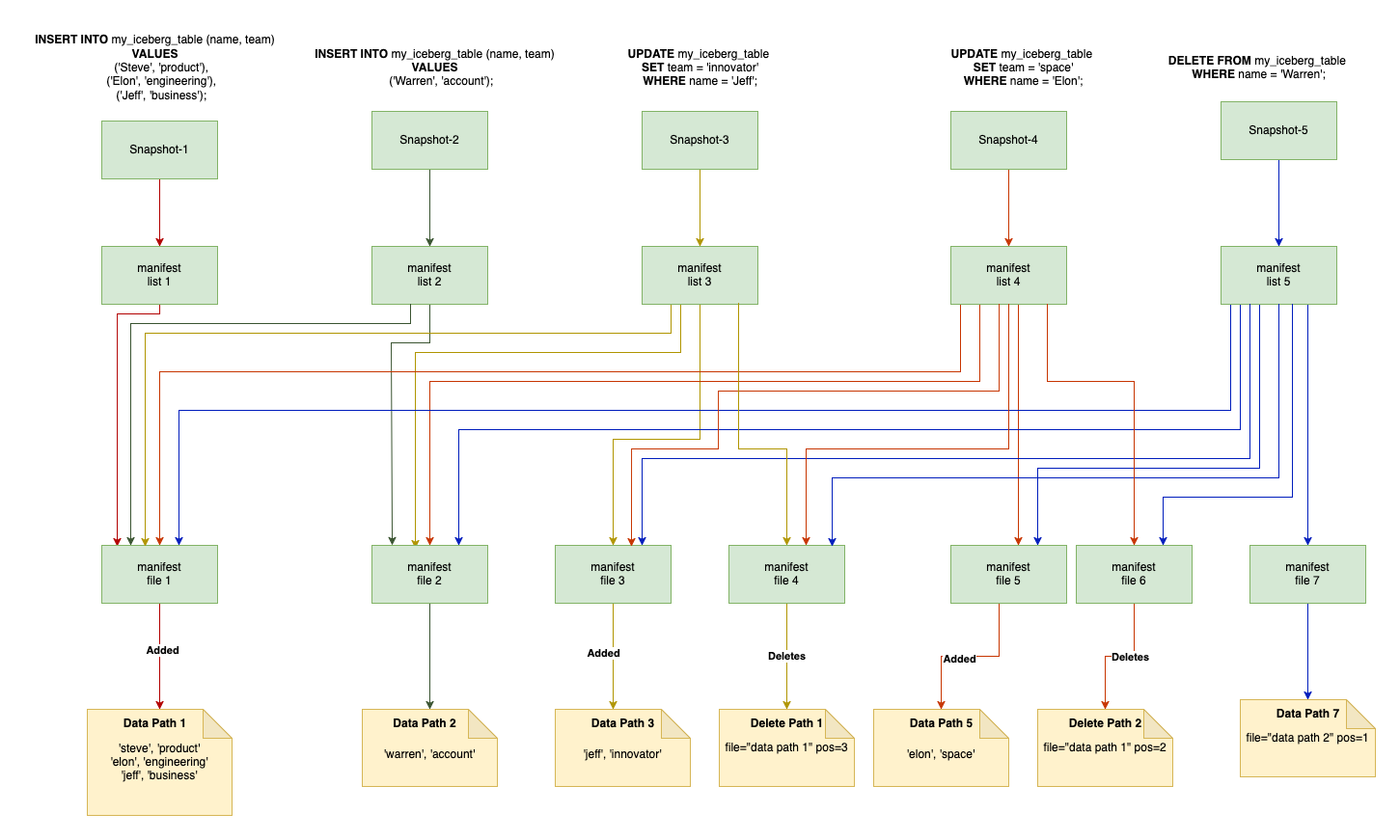
Detailed Example for Metadata store evolution During MOR - Positional Deletes
Will reuse the same queries and understand how the metadata store evolve with MOR.
INSERT INTO my_iceberg_table (name, team)
VALUES
('Steve', 'product'),
('Elon', 'engineering'),
('Jeff', 'business');
INSERT INTO my_iceberg_table (name, team)
VALUES
('Warren', 'account');
UPDATE my_iceberg_table
SET team = 'innovator' WHERE name = 'Jeff';
UPDATE my_iceberg_table
SET team = 'space' WHERE name = 'Elon';
DELETE FROM my_iceberg_table
WHERE name = 'Steve';
Note: For simplification I have not represented metadata file but only new snapshots created for every write.
Compaction
As you can see with MOR or COW, the number of manifest and data files will implode even with scale. As every write operate generates new snapshot. The performance will also take a hit as query engine will need to read many small files.
To mitigate this side effect, there are various Compaction capabilities to rewrite many small files into few large files. There are two types of compactions : data compaction and manifest compaction.
The goal with compaction is
- Reducing number of files - For MOR you can compact by applying the merge operation on the data.
- Improving the data locality - Essentially you have the freedom to sort it, or repartition it as per your use-case.
Will go in more details in next blog.
Control Flow Of Writes.
Above I tried to explain the table specifications defined by Iceberg. For understanding Iceberg protocol we will have to understand how the Iceberg library works. Iceberg provides a set of APIs that need to be implemented by different compute engine -
- AppendFiles
- For simply adding new files ( INSERT INTO operations).
- Interface - here
- Implementation - FastAppend
and MergeAppend
- As name suggest FastAppend simply adds a new manifest files to the metadata files (log of snapshots) while MergeAppend adds new manifest file and merge existing manifest files to reduce number of manifest files in check.
- OverwriteFiles
- For copy on write operations that performs row level changes (UPDATE, MERGE, DELETE).
- Interface - here
- Implementation - BaseOverwriteFiles
- RowDelta
- For read on merge operations that performs row level changes (UPDATE, MERGE, DELETE).
- Interface - here
- Implementation - BaseRowDelta
- RewriteFiles
- For Compaction.
- Interface - here
- Implementation - BaseRewriteFiles
NOTE - I will go deeper into the validations and data conflict checks in upcoming blogs.
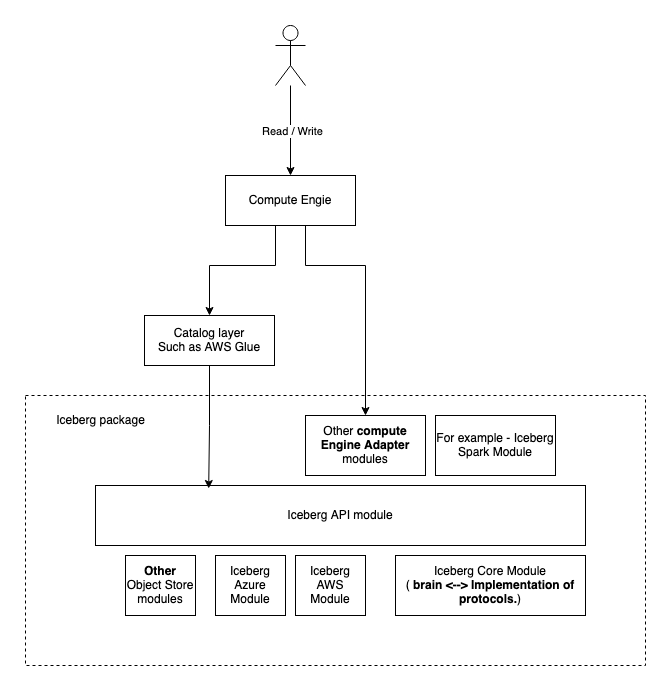
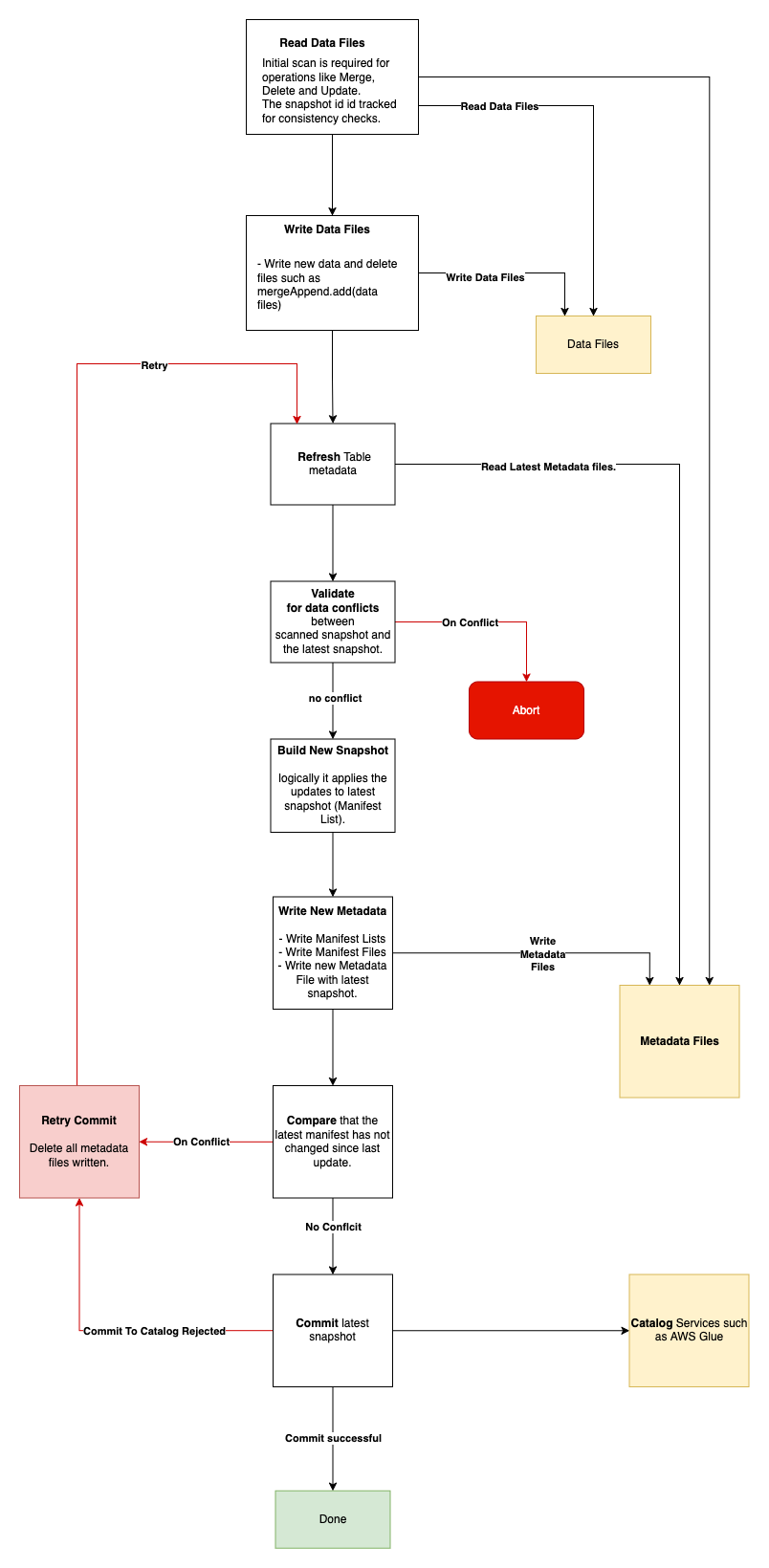
Simplified Iceberg Write control flow.
Interesting point to see here -
- Data conflict check happens before trying to commit. Is the data conflict is detected early it does not even try to commit.
- Commit to catalog uses compare and swap technique. It tries to compare the current snapshot id (acquire lock if required) and commit with new updated snapshot id. If commit results in conflict it tries to regenerate the manifest without retrying to rewrite the data files.
Appendix
In dept analysis of Iceberg Write control flow.
NOTE - I will go deeper and will explain it in details in concurrency blog.
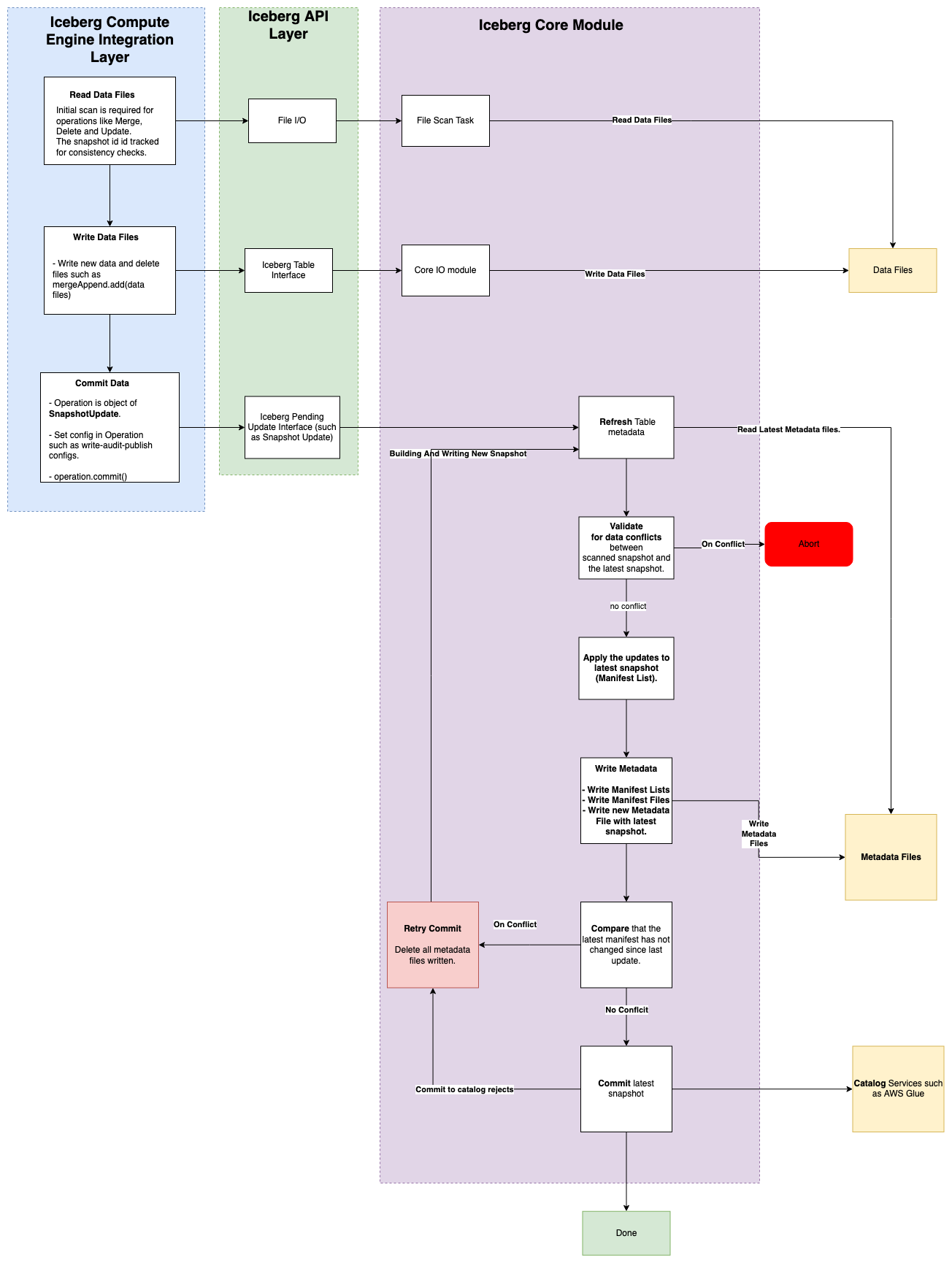
If you are interested to dive further down the rabbit hole, good way to start is from compute engine adapter module. I started from Apache Spark module, specifically SparkWrite Class.
Upcoming Blogs will talk about
- How Apache Iceberg does compaction ?
- How Apache Iceberg handle data conflicts ( essential for consistency ) ?
- How Apache Iceberg improves performance?
Reference
- Iceberg Code Base for understanding iceberg protocol
- Iceberg Official docs for understanding iceberg specification
- Apache Iceberg The Definitive Guide for highly understanding for Iceberg.