A formal model of crash recovery in distributed system
We are on a path to build a strong foundation in distributed systems. We have already gone over distributed time; the next topic we will cover is Distributed Consensus. To build the foundation on distributed consensus, we will go over the the paper ‘A Formal Model of Crash Recovery in a Distributed System’ published in 1983 by Skeen and Stonebraker. The purpose to understand this paper is to learn how to formalize the crash recovery problem in distributed database environment. This will set foundation on how to think and build mathematical framework for crash recovery problems.
Pre-requisite
Please go over basics of transactions, 2PC and Quorum based commit protocol for better understanding. My explanation and learnings on the topic can be found here.
Background
A transaction in distributed database systems is a logically atomic operations i.e. it must be present in all nodes or at none of them. Handling atomic operations of commit and abort in a single node is a well understood problem.
In multiple node (distributed environment) it the task of the commit protocol to enforce global atomicity. The basic purpose of commit protocol is getting consensus for all nodes to come to one decision of either committing or aborting the transaction. The challenge that commit protocol has to solve is getting the consensus in the face of failures e.g. node failures, network failures, transaction deadlock with another transaction, etc.
The fundamental idea in this paper is before any node can commit the transaction, all nodes must give up the right to unilaterally abort it. Once node gives up the right, it can abort the transaction only in concordance with other sites.
Motivation
The most basic commit protocol that allows nodes to unilaterally abort the transaction is 2-phase commit protocol. As discussed in previous blog, it is a centralized protocol with system getting blocked until the failures in coordinator is repaired.
Author argues that certainly blocking is an option to preserve consistency. It is an undesirable because the locks
acquired by blocked transactions can never be relinquished.
This motivates the author to focus on non-blocking protocol where operational nodes never suspend because of failure.
Author argues that the resilient protocol should always terminate irrespective of failures.
Transaction Model
Network Assumptions
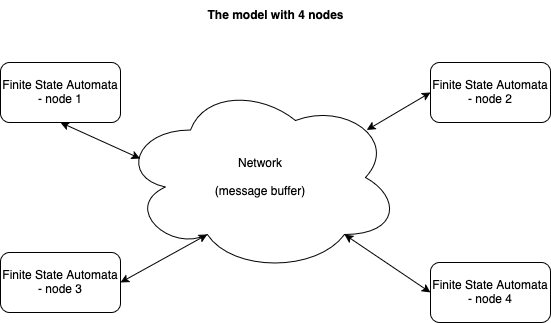
The network provides point to point communication i.e. any node can send a message to any other node. It assumes that either the message is delivered successfully within the time T or it reports a timeout to the sender.
Finite state Automata
The commit protocol can be specified in terms of non-deterministic finite state automata for each node. The final state will be either abort or commit to end the transaction.
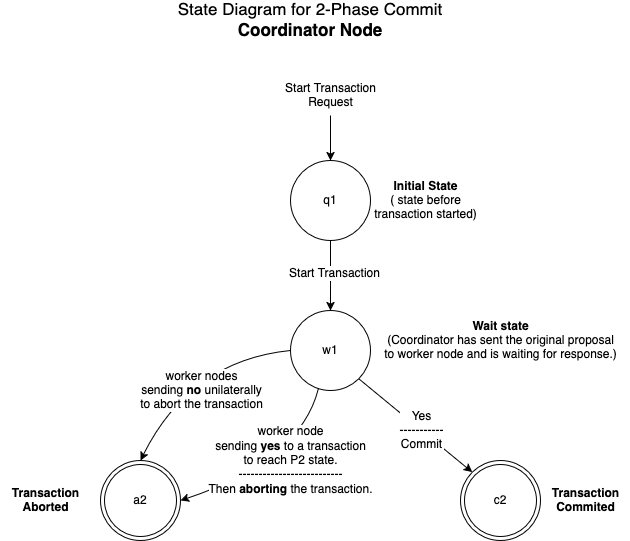
FSA for 2-phase commit protocol’s Coordinator node
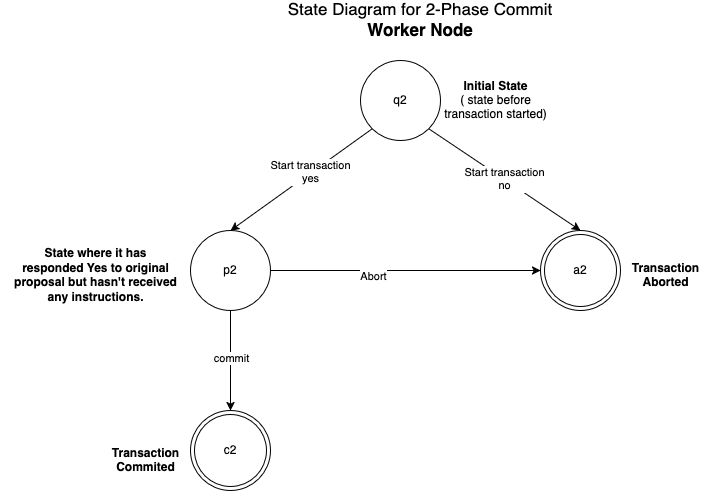
FSA for 2-phase commit protocol’s Worker node
Global Transaction State for 2-phase commit protocol
The paper defines global state as -
The global state of a distributed transaction is defined to consist of: 1) a global state vector containing the states of the local protocols, 2) the outstanding messages-in the network.
The Global state defines the complete process state of a transaction. A global state is a final state if all local states contained in its state vector are final states. It is said to be inconsistent if its state vector contains both a commit state and an abort state.
In simple terms it consists of all possible states that can happen at the same time. So, if at any time there can be multiple state possible, then it is said to be inconsistent.
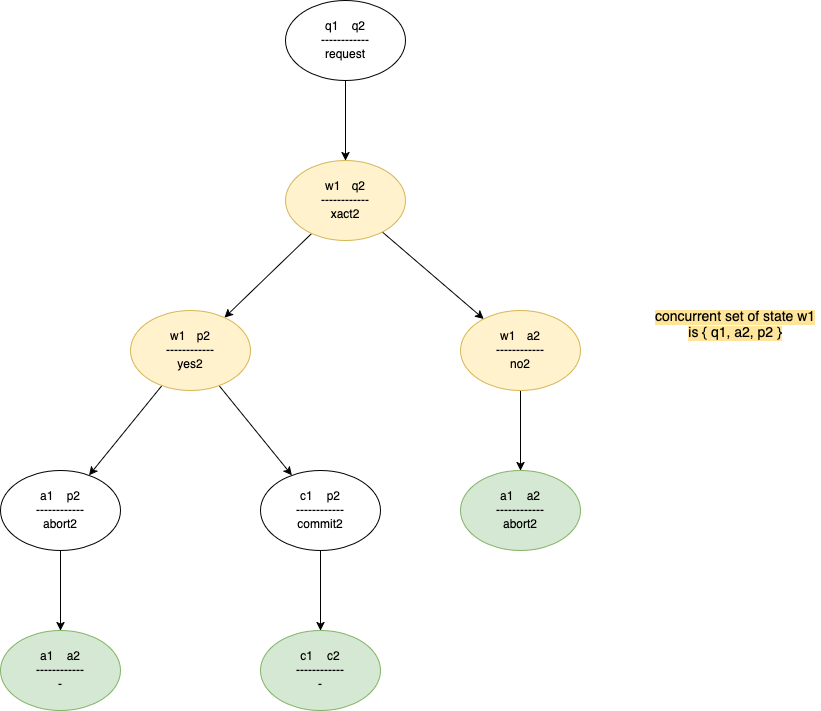
Concurrency Sets - The set of transactions that were active (in progress) at the time a node crashes. These are the transactions that were neither committed nor aborted at the time of the crash.
In above example The concurrency set of w1 is { q2, a2, p2}. A node at w1 knows that other node will be one of these state.
Independent Recovery
The author argues that we need an independent recovery protocol in case of failures because acquiring state and history
from other nodes may fail.
Personal opinion: I am not sure about it, I doubt such an algorithm can have practical use case.
Author defines independent recovery as the protocol that recovers solely based on its own local state, without communicating to other nodes.
Personal opinion: Yes, this approach reduces the complexity by reducing the failure scenarios of nodes trying to acquire status of other nodes. But I doubt its practicality.
Recovery Rules of a single failed node
Author tries to come up with rules to define what should a node do in case of single node failure.
Lemma 1: If a concurrency set contains both a commit and an abort, then the protocol is not resilient against failure. By definition of concurrency set, choosing one state will lead to inconsistent results.
If they are not in consistent set, we can create a protocol that is resilient against single node failure from the following rules (Theorem 2)
- Rule 1: If a node’s concurrency set contains a commit, the node should commit. Otherwise, abort
- Rule 2: If another node is in a state s1 where it could get a messages from a node in state t1, but it hasn’t received a message at the timeout, it must do the same as t1’s failure behavior. Anything else would be inconsistent.
Example - 2-Phase Commit does not satisfy lemma 1 but it can be modified to do so with an acknowledgement.
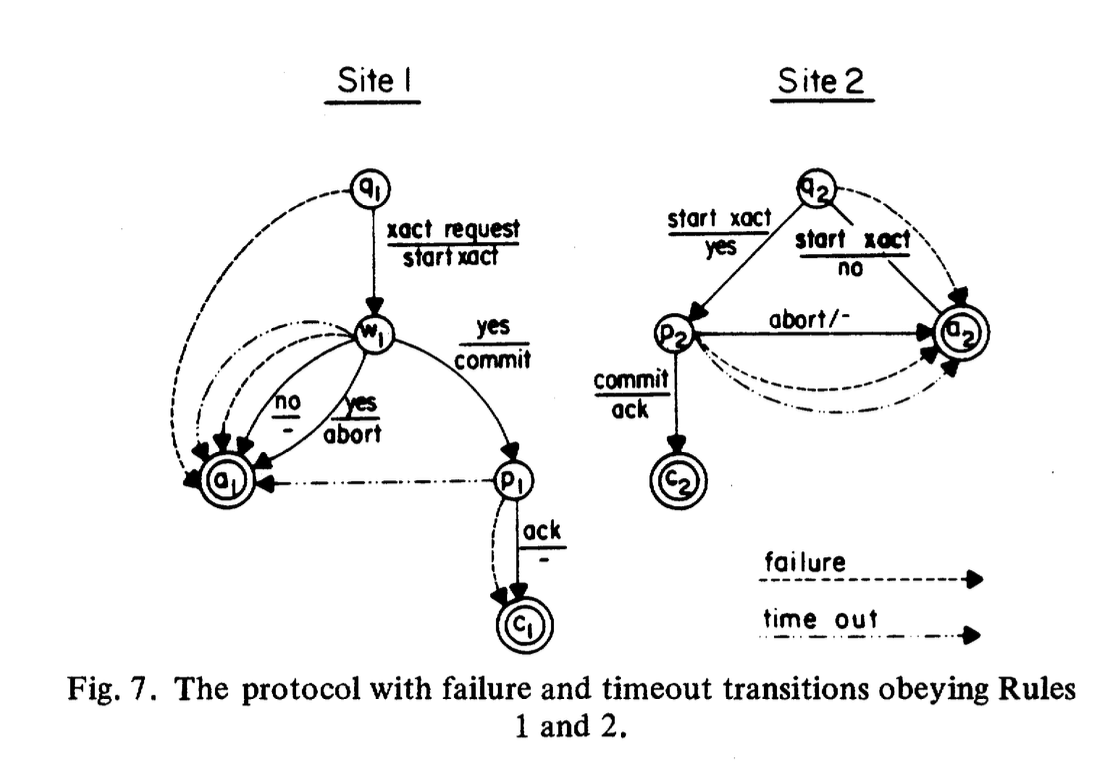
Limitations of independent recovery
Can this be extended to multi node failures?
The paper provides theorem 3 defining there is no protocol using independent recovery that is resilient to multi node
failures. The paper also provides the proof for same.
Can this be extended to network partitioning?
The paper provides theorem 4 defining there exists no (nonblocking) protocol resilient to a network partitioning when messages are
lost. The paper also provides the proof for same.
Personal opinion: Multi node failures and partitioning is the reality of the world, thus I doubt how useful is independent recovery is.
Learnings
I think the major motivation of the paper was provoke thinking and reasoning to find a non blocking protocol. Even though it proves it is not possible.
I found the bellow learnings useful, overall the paper was too dense with mathematical proofs -
- The mental model of global states can be useful in distributed system while thinking about complex problems.
- The nondeterministic finite state machine for commit protocol, is also a useful tool while reasoning about the complex state transitions specially in databases.